
Data Mesh Architecture: Extend an existing operational COTS application using cloud-based HA/DR to build out an analytics platform
Abstract
Data Mesh seems most aligned with the principles derived from Cloud Native Apps and Microservices. What about existing applications and databases? Can you embrace Data Mesh fundamentals to extend an existing operational Commercial off-the-shelf (COTS) application using cloud-based High Availability and Disaster Recovery (HA/DR) features to replicate operational databases and build out an analytics platform? How can a source-aligned data domain that is not custom built, feed into your data architecture? It’s a buy vs build world that is never a green field. What about extending a vendor application to collect new data or provide some new AI capability?
Introduction
Organizations have many COTS and custom-built apps that are backed by relational database management systems (RDBMS) from commercial vendor products like Microsoft SQL Server, and Oracle Database as well as open-source RDBMS like PostgreSQL and MySQL. I am going to focus on SQL Server and Oracle in this post and look at using HA/DR capabilities and architectures not only for business continuity, but also to support read-only secondary replicas for analytical purposes. I will also focus on Azure examples but there is no reason these ideas can’t be used in on-premises data centers as well as public cloud datacenters like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Oracle cloud infrastructure (OCI). In fact these could be hybrid scenarios where the primary application and database are on-premises and the secondary application and database reside on a public cloud; or where two Azure availability zones are used for failover while another Azure region is used for an analytical read-only secondary.
SQL Server and Azure SQL Managed Instance
One of my favorite features that went GA recently with SQL Server 2022 is Managed Instance link. This feature enables near real-time data replication from SQL Server to Azure SQL Managed Instance. The SQL Server can be on-premises or running in Azure on an IaaS VM. In a scenario where you had an on-premises application backed by SQL Server, the ready-only replica on Azure SQL MI could be used to do the following:
- Perform Automated Backups after databases are replicated to managed instance, they are automatically backed up to Azure Blob Storage account with Azure Backup.
- Offload Read-only Workloads to SQL Managed Instance deployments in any Azure region worldwide
- Enable Analytics and App Integration Use Cases by taking advantage of Azure services by using SQL Server data without migrating the primary SQL Server to the cloud. Examples include reporting, analytics, machine learning, and other jobs that integrate data with resources on Azure.
Here is how the managed instance link feature works:
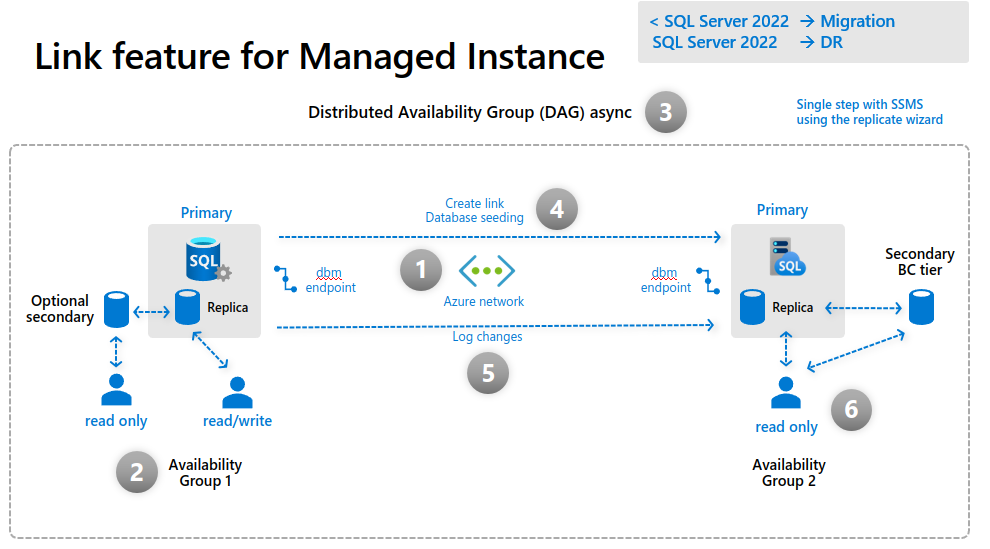 )
)
This slide is from a SQL Server 2022 presentation by Bob Ward and Buck Woody
Similar replication of primary read-write databases to read-only failovers replicas or read-only secondaries can be done using Always-on availability groups.
Oracle Database and Oracle Active Data Guard
I am currently working with a customer that is migrating their entire on-premises data center to Azure. As part of the process, they have numerous applications backed by Oracle Databases that need to be lifted and shifted to Azure. Just like SQL Server Always-on availability groups, Oracle has a capability called Active Data Guard that can be used for HA/DR and read-only secondaries.
Here is how Oracle Active Data Guard and Oracle Database running on Azure Linux IaaS VMs can be used for HA/DR and replication for reporting and analytics:
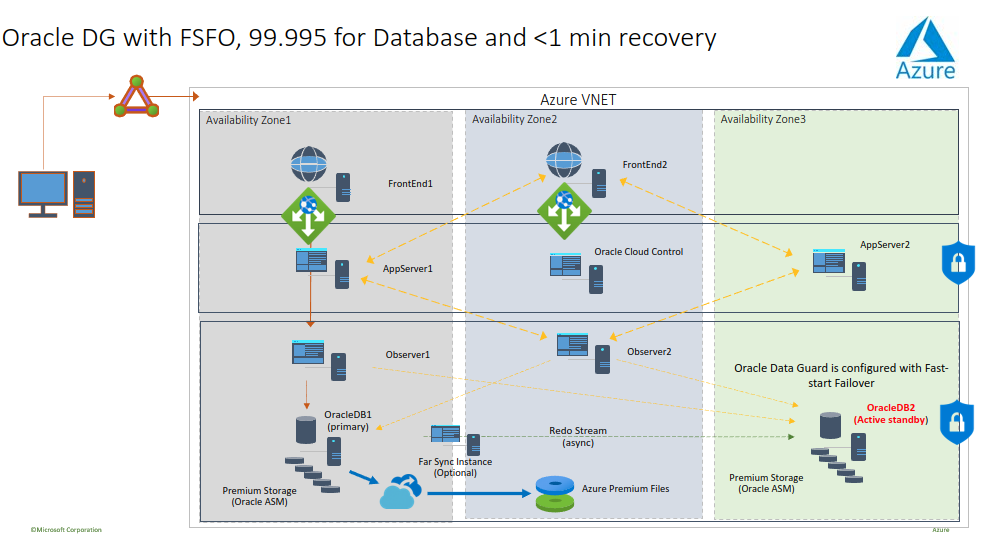
This slide is from a Kellyn Gorman who works with Azure Customers to migrate their Oracle workloads to Azure
Change Data Capture (CDC)
Azure Data Factory CDC
Take a look at Mark Kromer’s demo of the CDC feature in Azure Data Factory Change data capture resource overview
Or checkout Change Data Capture and Managed Airflow in Azure Data Factory | Azure Friday
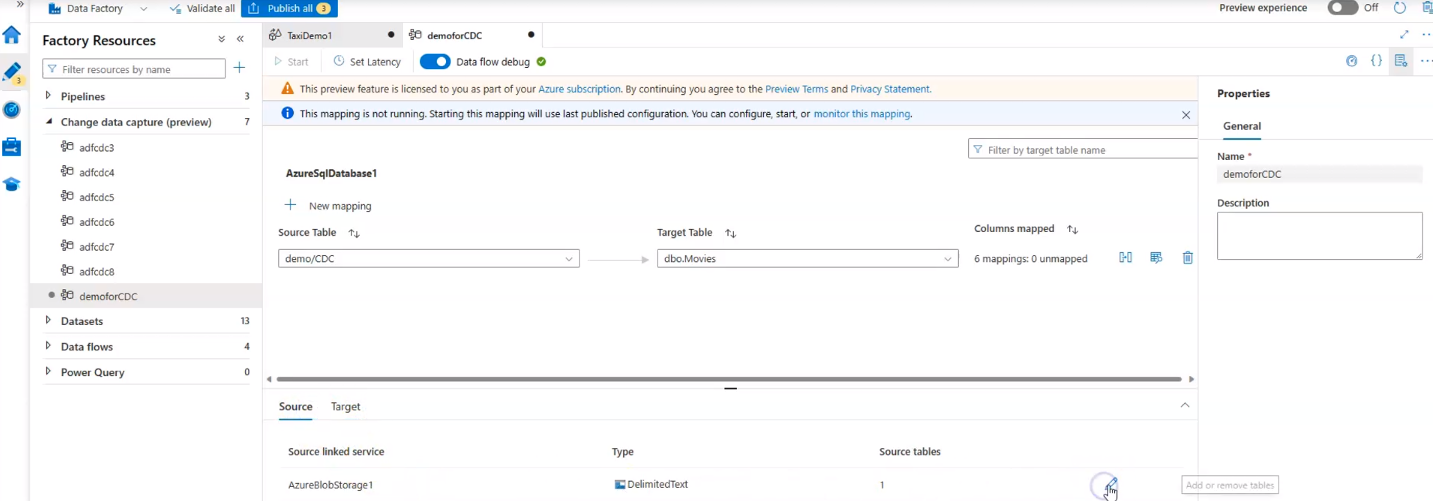
ADF, SQL Database, and Databricks Azure Analytics Accelerator
Here is an example that uses an ADF Pipeline to move changes in an Azure SQL database to Azure ADLS storage. Autoloader is then used in a Databricks notebook to pick up the files and stream the changes into a Delta table in Azure Databricks
I have more details in my post Data Architecture and Designing for Change in the Age of Digital Transformation
Get the Data into a Lakehouse
Data Mesh and CDC can help get data into a Lakehouse Architecture to help with reporting, analytics, AI, machine learning, and integration use cases on Azure. I hope you come back to read other posts on these topics!
Edited by Joey Brakefield. Thanks Joey. Proof I need to write these in Word and not only as markdown in VSCode.